


Qu’est ce qu’un LLM ?
Développé par OpenAI, GPT est un des LLM (« Large Language Model » ou « Grand modèle linguistique » en français) les plus populaires. Il en existe bien d’autres. Google a développé PaLM 2, Meta a développé Llama 2, et Anthropic a développé Claude 2.
Une des capacités les plus connus des LLMs est de faire de la complétion de texte. De nombreuses applications en découlent par exemple :
- Résumer des textes (Comme par exemple Jus Mundi)
- Créer des chatbots ou des assistants virtuels (comme par exemple ChatGPT)
- Aider à la création de contenu
- Traduire
- Extraire des données
- Faire de la classification de données
- Répondre à des questions
- Changer le ton d’un texte
- Corriger l’orthographe ou la grammaire d’un texte (ce que j’ai fait avec GPTChat pour cet article)
Si vous êtes un développeur, vous pouvez avoir des exemples dans mon précédent article : https://medium.com/@thomas.latterner/example-and-feedback-of-using-chatgpt-for-developers-60f7a12158cb
Définitions et Capacités des LLM
Les LLMs sont des modèles de Machine Learning basés sur une architecture de transformer, utilisant de l’intelligence artificielle générative pour effectuer des tâches de traitement du langage naturel (NLP).
Outre la complétion de texte, les LLM peuvent être adaptés pour une variété de tâches en NLP. Par exemple, ils peuvent être utilisés pour la détection d’émotions dans le texte, la classification de documents, la reconnaissance d’entités nommées, et bien d’autres.
Un modèle de Machine Learning est un algorithme ou une formule mathématique qui permet à un ordinateur d’apprendre à partir de données. Au lieu d’être explicitement programmé pour effectuer une tâche, il utilise des données pour faire des prédictions ou prendre des décisions.
L’architecture « transformer » est une structure spécifique utilisée dans le Machine Learning pour traiter des séquences de données, comme le texte. Elle est particulièrement puissante pour comprendre les dépendances à long terme dans les données.
L’intelligence artificielle générative fait référence aux modèles d’intelligence artificielle qui peuvent créer de nouveaux contenus. Dans le contexte des LLM, cela signifie générer du texte qui n’existait pas auparavant.
Le traitement du langage naturel (NLP) est une branche de l’intelligence artificielle qui se concentre sur la communication entre les ordinateurs et les humains via le langage naturel. Cela peut inclure la compréhension, la génération ou la traduction de texte.
Pour synthétiser : Les LLMs sont des modèles d’IA qui utilisent l’architecture « transformer » pour apprendre et générer du texte. Ils ne sont pas programmés spécifiquement, mais apprennent à partir de données. Ces modèles peuvent comprendre et créer du contenu en langage naturel, comme traduire ou générer du texte.
Processus d’apprentissage et coût
Au cours de son processus d’apprentissage, le modèle apprend les relations statistiques entre les mots, les phrases et les paragraphes, ce qui lui permet de générer des réponses cohérentes et pertinentes au contexte lorsqu’il reçoit une instruction ou une requête.
L’apprentissage d’un modèle de machine learning, expliqué simplement, c’est comme enseigner à un enfant comment résoudre un problème en lui montrant de nombreux exemples. Au fil du temps, en voyant assez d’exemples, l’enfant (ou le modèle) apprend à reconnaître des schémas ou des tendances et peut ensuite utiliser ce qu’il a appris pour résoudre de nouveaux problèmes similaires à ceux qu’il a déjà vus.
L’apprentissage des LLM nécessite beaucoup de temps, de ressources et d’énergie. Cela nécessite aussi une grande quantité de données de bonne qualité. La combinaison de ces prérequis fait que seules certaines grandes entreprises peuvent entraîner ce genre de modèle. Il existe des modèles open source que vous pouvez trouver, par exemple, sur Hugging Face, qui sont plus ou moins bons, mais qui peinent à rivaliser avec GPT (en termes de capacités et de raisonnement).
Pour vous mettre cela en perspective, selon certaines estimations, l’entraînement de GPT-3 aurait nécessité 570Gb de données (soit l’équivalent d’environ 300 milliards de mots) et consommé 1287 gigawatt heure (l’équivalent de la consommation d’une centaine de foyers américains par an). Il faut aussi ajouter à cela le coût humain en recherche et développement ainsi que les superviseurs ayant pour rôle d’indiquer au modèle les bonnes réponses. En plus du coût d’entraînement, il y a celui lié au fonctionnement quotidien, s’élevant à approximativement 700k$ par jour.
En étant entraîné sur cette immense quantité de texte, un LLM comme GPT-3 peut ensuite comprendre plusieurs langues et posséder des connaissances sur divers sujets. C’est pourquoi il peut produire du texte dans différents styles.
Compréhension du texte
La clé pour permettre à un LLM de comprendre un texte et fournir des réponses de qualité réside à la fois dans la fenêtre de contexte et le mécanisme d’attention. Le mécanisme d’attention permet au modèle de comprendre les relations entre les mots, les phrases, et les paragraphes, et donc, de saisir la signification profonde d’un texte. La fenêtre de contexte, quant à elle, est le nombre maximal de mots que le modèle peut à la fois utiliser pour générer sa réponse et s’y référer pour garder un historique et avoir accès à de nouvelles données. Il ne s’agit pas vraiment de mot, mais de token. Un token peut être aussi court qu’une lettre ou aussi long qu’un mot. Par exemple, « ChatGPT » pourrait être divisé en « Chat » et « GPT », chacun étant un token.
Le problème actuel de la fenêtre de contexte est qu’elle est très coûteuse en ressources (mémoire et calcul). Pour chaque nouveau mot, il faut que le modèle comprenne son sens et la relation qu’il entretient dans le texte avec les autres mots. On parle d’une relation x4 (quadratique). Pour vous donner un ordre d’idée, la puisse 4 de 15 est : 15<sup>4</sup> = 15 x 15 x 15 x 15 = 50,625, et la puissance 4 de 30 est : 30<sup>4</sup> = 810,00. 30 est le double de 15, alors que la puissance 4 de 30 équivaut à 16 fois la puissance de 15. C’est ce qu’on applle une relation exponentielle. Pour faire une analogie, c’est la même chose que la consommation d’essence d’une voiture. Plus vous roulez vite, moins vous pourrez faire de distance avec une même quantité d’essence. Cette consommation exponentielle de ressources limite de facto la compréhension d’un texte dans son intégralité, la quantité totale de texte pouvant être envoyée au LLM et utilisée pour la réponse.
Cette limite est de maximum 32,768 tokens (environ 25 000 mots) pour GPT-4 et 100,000 tokens (75 000 mots) pour Claude, le LLM d’Anthropic.
Plus cette fenêtre est grande, plus elle permet au modèle :
- D’être performant, de produire un meilleur « raisonnement »
- De comprendre des concepts ou des textes plus complexes
- De générer des réponses plus justes et précises
- D’avoir accès à un historique de conversation plus long, de mieux se souvenir, et donc de conserver une cohérence et qualité conversationnelle
Vous comprenez pourquoi le mécanisme d’attention est crucial pour améliorer la qualité des LLMs.
Il est important de noter que les LLM ne comprennent rien. Ni le langage humain, ni la signification derrière les mots et les phrases. Ils capturent et reproduisent les schémas statistiques des milliards de phrases qu’ils ont vues pendant leur phase d’apprentissage.
Qu’est ce que GPT et ChatGPT ?
GPT, pour Generative Pre-trained Transformers, est le LLM développé par la société américaine OpenAI. La première version de ce modèle a été publiée en 2018. Il s’est ensuivi plusieurs versions jusqu’à la dernière en date, GPT-4 sortie en mars 2023.
Au-delà de sa capacité à générer du texte, GPT a révolutionné la manière dont nous interagissons avec cette technologie. Sa capacité à comprendre et à répondre de manière contextuelle a ouvert la voie à des applications plus avancées dans divers domaines. Vous aurez pu le constater vous-même, depuis quelques mois, énormément de produit propose aujourd’hui de nouvelles fonctionnalités boostées à l’IA, et notamment aux LLM.
ChatGPT est une interface qui permet d’utiliser deux versions de GPT (3.5 et 4) dans un navigateur web ou via une application sur Android ou iOS. Vous pouvez accéder à sa version gratuite en créant un compte OpenAI ou opter pour sa version payante. En souscrivant au service « ChatGPT plus », vous bénéficiez de réponses plus rapides, d’un accès prioritaire lors des pics d’affluence et d’un accès en avant-première aux nouveautés telles que GPT-4. Les équipes d’OpenAI améliorent continuellement ChatGPT grâce aux conversations des utilisateurs. Elles ont accès à l’historique de vos conversations et peuvent l’utiliser à cette fin. Soyez donc prudent quant aux informations que vous partagez ! Bien que vous puissiez désactiver l’historique des conversations pour ne pas contribuer à cette amélioration, cela n’empêche pas certains employés d’OpenAI d’accéder à vos échanges, car ils sont conservés pendant plusieurs jours afin de s’assurer que vous n’utilisez pas le service de manière frauduleuse.
Ci-dessous, vous trouverez une capture d’écran de l’interface de ChatGPT, accompagnée de quelques explications pour ceux qui sont moins familiers avec l’outil :
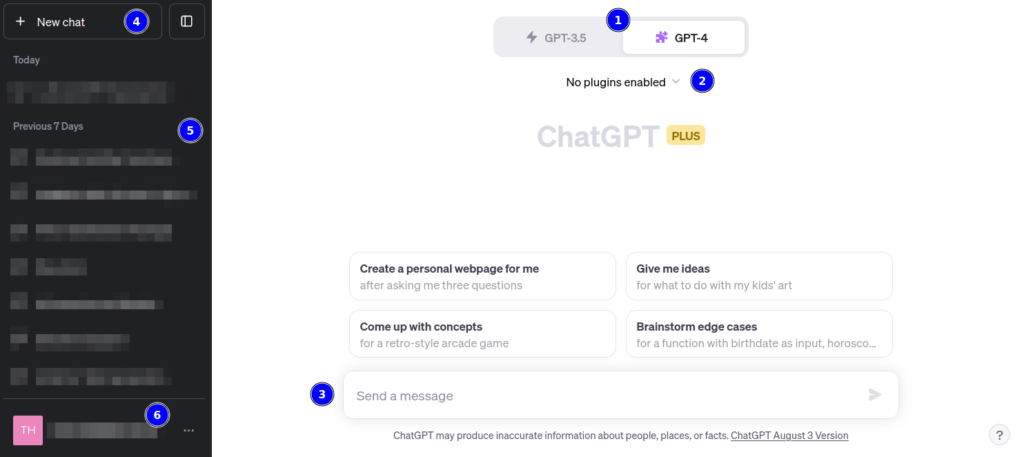
- Sélection du modèle souhaité
- Possibilité d’ajouter jusqu’à 3 plugins pour votre prochaine conversation (cela permet, par exemple, de générer un PDF ou d’effectuer une recherche via un service tiers. Certains peuvent être payants).
- Champ destiné à la saisie de votre prompt
- Bouton pour créer une nouvelle conversation
- Accès à l’historique de vos conversations précédentes
- Gestion de votre abonnement et de vos préférences
GPT est également accessible via une API, ce qui élimine la nécessité d’une interface « humaine » directe. Une API, acronyme d' »Interface de Programmation d’Applications », est un ensemble de règles et de spécifications qui permettent aux logiciels d’interagir et de communiquer entre eux. Grâce à une API, les applications peuvent échanger des informations ou des données sans avoir à connaître les détails internes de leur fonctionnement. Cela assure l’interopérabilité entre différents systèmes. Pour GPT, OpenAI a mis à disposition un ensemble d’APIs afin de permettre aux développeurs d’intégrer les capacités de ce LLM dans leurs propres applications ou plateformes. Toutefois, l’utilisation de cette API n’est pas gratuite. OpenAI a adopté un modèle de tarification basé sur l’usage : pour chaque tranche de 1000 tokens (unités de texte) utilisés, que ce soit pour la question posée ou la réponse générée, des frais s’appliquent.
Conclusion
Les LLM, comme GPT, représentent une avancée majeure dans le domaine de l’intelligence artificielle et du traitement du langage naturel. Leur capacité à comprendre, générer et interagir en langage naturel ouvre la porte à d’innombrables applications qui étaient autrefois difficiles à mettre en place. Cependant, comme pour toute technologie, il est essentiel de l’utiliser judicieusement et de comprendre ses limites, ce qui sera le sujet de mon prochain article.
Sources
- https://machinelearningmastery.com/what-are-large-language-models/
- https://www.allabtai.com/gpt-4-prompt-engineering-why-larger-context-window-is-a-game-changer/
- https://www.lebigdata.fr/argent-energie-vrai-cout-chatgpt
